Digitize a Batch Record¶
In this tutorial you will digitize a PDF batch record. Critical process data shouldn’t stay trapped in PDFs. Start to analyze data from PDFs in less than five minutes.

|
|
Get an API key¶
You’ll need an API key to follow along with this tutorial. Get a temporary API key sent to you by email.
How to use this tutorial¶
There are three ways to follow along with the tutorial (from beginner to advanced):
Run the code in the cloud. Without installing anything locally, you’ll be able to both change and run the code. Open the Colab notebook.
Download the code as a Jupyter notebook:
batch-record-digitization.ipynb. First-time users of Jupyter notebooks should follow the Getting Started instructions first.Copy and paste the code snippets below into your own Python development environment.
Install the fathomdata library¶
From a terminal:
$ pip install fathomdata
Confirm the installation was successful by importing the library. We name the library fd on import by convention.
import fathomdata as fd
Users who are new to Python can find more detailed instructions at Getting Started.
Digitize a batch record¶
Download a sample batch record, or use the code below to download it programmatically.
with open("batch3.pdf", "wb") as f:
pdf = fd.get_sample_batch_record("batch3")
f.write(pdf)
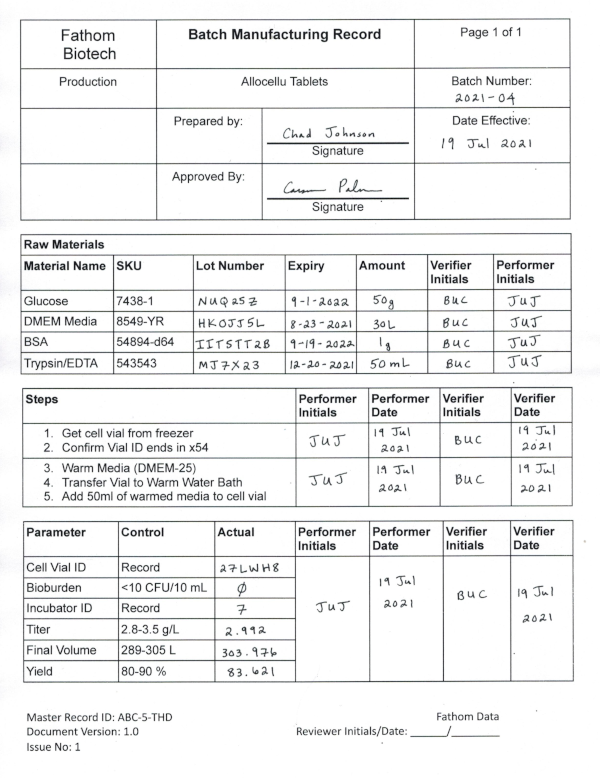
Take a moment to look at the example batch record PDF. If you didn’t change the path above, the PDF will be saved in your current working directory. You can also open it programmatically.
This batch record contains many different types of data from raw material sources to process metrics. There is a mix of handwritten and typed text and the formatting varies throughout the record. For this tutorial, we’ll focus on extracting and cleaning any type of data stored in a table (but this is just the start!).
Set your API key for this session.
Tip
Keep your API as an environment variable to prevent you from accidentally checking it into a git repository.
apikey = 'your-api-key-goes-here'
fd.set_api_key(apikey)
Now, digitize the batch record using ingest_document.
new_doc_id = fd.ingest_document("batch3.pdf") #update path to download location
print(f"Ingested document with ID {new_doc_id}")
Ingested document with ID 65aab1e5-0031-4679-9f66-eb4930ea6c6d-0
That’s it! Check that the upload was successful by listing the available records.
df = fd.available_documents()
df.head()
| DocumentId | ReceivedTime | Filename | UploadedByUserId |
|---|---|---|---|
| 65aab1e5-0031-4679-9f66-eb4930ea6c6d-0 | 07-20-2021 05:37PM | batch3.pdf | demo@fathom.one |
If the df syntax look familiar, that’s because fathomdata is built on top of pandas. You can interact with this record dataframe using all the pandas slicing and indexing tools .
Take a moment to repeat the process and digitize a new sample record. Download the batch4 pdf here or use the first code block above to download it programmatically. Then re-run the rest of the commands, but replace batch3 with batch4. When you are done, your available documents dataframe should look something like this (plus a few columns we hid for space).
| DocumentId | ReceivedTime | Filename | UploadedByUserId |
|---|---|---|---|
| 65aab1e5-0031-4679-9f66-eb4930ea6c6d-0 | 07-20-2021 05:37PM | batch3.pdf | demo@fathom.one |
| 9a4000c8-edf3-4bbf-a78e-4f3f235aae90-0 | 07-20-2021 05:38PM | batch4.pdf | demo@fathom.one |
Use the digitized data¶
The extracted data is also returned in a pandas dataframe so it’s quickly available for custom analysis.
doc = fd.get_document(new_doc_id)
materials = doc.get_materials_df()
materials.head()
| SKU | Lot Number | Expiry | Amount | Verifier Initials | Performer Initials | |
|---|---|---|---|---|---|---|
| Glucose | 7438-1 | NUQ25Z | 2022-09-01T00:00:00 | 50g | BUC | JUJ |
| DMEM Media | 8549-YR | HKOJJ5L | 2021-08-23T00:00:00 | 30L | BUC | JUJ |
| BSA | 54894-d64 | IITSTT2B | 2022-09-19T00:00:00 | 1g | BUC | JUJ |
| Trypsin/EDTA | 543543 | MJ7X23 | 2021-12-20T00:00:00 | 50 mL | BUC | JUJ |
Next you can try some statistical process control analytics using this data.